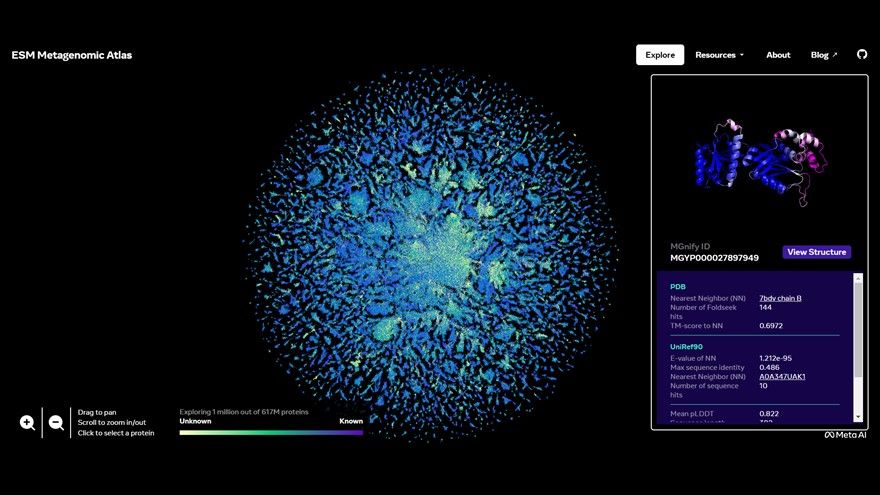



Meta指出,ESMFold所預測出的蛋白質結構資料庫ESM Metagenomic Atlas,是全球首個最大規模的蛋白質預測資料庫,讓人類對於蛋白質結構的了解進入的全新世代。同時,也公開分享該資料庫以及AI模型。
雖然ESMFold和AlphaFold都是預測蛋白質結構的工具,但兩者的策略完全不同,AlphaFold是利用蛋白質原始序列和DNA編碼進行比對,從中預測蛋白質可能形狀及結構,ESMFold則是僅透過胺基酸序列便能進行結構預測。
ESMFold特別的地方在於,它是運用大型語言模型(large language model, LLM)進行蛋白質結構預測,該模型可以透過幾個字母、單詞來預測文本,研究團隊認為,蛋白質結構也同樣是由20種胺基酸所構成,這些胺基酸就如同構成文本的字母一樣。
而通常語言模型需要大量文本進行訓練,也需要結合上下文語境才能預測適合文字;研究人員為了將該模型運用至蛋白質結構預測上,便輸入已知蛋白質的胺基酸序列,並特意留出一些空白,語言模型就會像處理文本一樣,自動填補空白,得出完整的序列。
因此,研究人員就運用蛋白質數據庫中的大量已知結構,來監督、訓練ESMFold預測蛋白質3D結構的能力,甚至過程中也運用了AlphaFold先前的蛋白質結構預測數據庫,來提升ESMFold的預測能力。
最終,Meta AI團隊創建出至今為止最大的蛋白質結構預測數據庫,並且達到原子等級的準確度。
Meta AI蛋白質團隊的研究負責人Alexander Rives表示,由於ESMFold是直接利用胺基酸序列進行預測,因此流程比AlphaFold更簡單,在預測短序列結構上,速度最高可達到AlphaFold的60倍,可以快速擴展出更大的數據庫。
不過,Rives也指出,ESMFold整體的準確度不如AlphaFold。
為驗證ESMFold的預測,研究團隊對環境土壤、海水、人的腸道與皮膚以及其他微生物棲息場所採集樣本,進行了總體基因體學(Metagenomics)DNA定序,ESMFold僅用兩週的時間,就預測出超過6.17億個蛋白質結構,其中至少有2.25億個蛋白質結構屬於高準確度預測,不僅整體蛋白質形態正確,甚至有些能精準預測出原子層面的細節。
而在這6億多個蛋白質結構預測中,有76.8%與現有的蛋白質結構具有差異,有12.6%與經實驗驗證的蛋白質結構完全不匹配,代表ESMFold可以預測出大量目前未知的蛋白質結構。
未參與研究的首爾大學(Seoul National University)計算生物學家(computational biologist) Martin Steinegger評論,AlphaFold數據庫有很大一部分幾乎由相同結構組成,而ESMFold創建的數據庫應該涵蓋了以前未知的蛋白質宇宙,並有望解開更多未知之謎。
參考資料:https://www.nature.com/articles/d41586-022-03539-1
doi:https ://doi.org/10.1101/2022.07.20.500902
ESM Metagenomic Atlas蛋白質結構資料庫:https://esmatlas.com/
ESMFold AI模型:https://github.com/facebookresearch/esm
(編譯/李林璦)